An LLM blog post
Large language models are all the rage these days. Everyone’s working on them (or else 😰) and they’re showing up in everything. I have not been a fan though I do see the appeal of natural language programming, boiler plate free development, and of capturing the expertises of transient humans. That said, I get the sense that the hype is coming less from the theory, design, or scale behind statistical language models and more from a desire to degrade the economic value held by cantankerous humans. It’s worth noting up front that we’ve been here before. We’ve made languages designed for the everyman. We’ve made chatbots that have convinced us of their intelligence. We’ve made systems designed to capture the expertise of those we employ in an effort to scale the individual/reduce the relative value of labor. We are not without history and we are not without observable results. What’s that saying? Those who cannot remember the past are destined to meet their KPIs? I dunno, something like that.
Language models. What are they good for? Are they good at things? Lets find out!
What are we doing here
There’s a basic tool design I’ve seen a few times now; have a language model generate some text, show it to a human and ask 👍/👎❓. The stated goal is to aid the human by reducing some mundane work that the human is required to do at the moment. What’s ignored is that to read and to understand IS the job. To shortcut that is to abdicate the responsibility of the expert at the helm. These tools will only lead to accountability sinks where a mistake is blamed on the operator who will in turn blame the blackbox tool who’s designers will in turn blame the training data. Who ends up owning any given mistake will likely be down to organizational favoritism.
Automation is not the enemy. The lack of accountability is and if we’re going try to automate something in the vulnerability management space then we need to be serious about our goals. Do we want language models to write advisory descriptions? Do we want them to score severity? Do we even have a sense of what they’re good at? I haven’t seen anyone at all look at this space and actually ask questions of the tools, so lets do that here.
Pelicans
A few months back I came across the a fascinating language model benchmark. The so called Pelicans on a bicycle benchmark. The basic idea is to ask a language model to generate some novel new thing and then to iterate on the output asking the model to “improve” the output. While not something that can be objectively measured one can tease out what “improvement” is for each of the models.
The experiment
So, pelicans. The pelicans experiment lets us tease out what is meant by “improvement” in a visual sense. We ask a model to generate some content, “improve” it, observe the results, and see if anything sticks out. We can do that with advisories as well. My experiment is quite simple:
- Randomly generate a prompt
- Ask a model to generate a report based on the prompt
- Have the model “improve” the advisory in a loop
The results are primarily subjective. The code for this experiment is fairly compact and is available below
Buy local
Any good experiment attempts to reduce the number of variables to as few as possible and the ever changing nature of hosted language models makes it functionally impossible to design a repeatable experiment. Therefore they are not useful to me. Thankfully language models are just code and a number of open source (open weight?) models are floating around online. For this escapade I’ve gone with models available on huggingface.co. In particular I settled on the phi-4, Qwen-2.5 (7B), and DeepSeek-R1-Distill-Llama-8B. I played with a few other models, but these three had reasonable reputations and would run on my laptop (m1 max w/ 64GB) in a reasonable amount of time. I had hoped to use the recent gpt-oss-20b, however it seems that for macs an m2 or later is required.
The results
So, what do the results look like? Sloppy. Each of these shows the model, the initial non-llm text prompt and 6 “generations”. The first being the initial “write me an advisory” prompt and the other five being the improvement loop.
Here’s one example:
{
"model": "Qwen/Qwen2.5-7B",
"input_prompt": "The product named An actual car which has a medium severity logic injection vulnerability in user settings in the versions since but not including five point two two six up to one hundred and nineteen",
"generations": [
"The actual car product has a logic injection vulnerability in the user settings in the versions since but not including five point two two six up to one hundred and nineteen\nccording to the vulnerability description, an attacker can modify the user's settings by submitting malicious input, leading to unauthorized changes in the user's account or system behavior. This could result in sensitive data exposure or loss of system integrity.\n\nTo mitigate this vulnerability, we recommend upgrading to version five point two two six or later. Additionally, we advise implementing proper input validation and sanitization measures to prevent unauthorized modifications to user settings.\n\nFor more information on this vulnerability and recommended mitigation steps, please refer to the official security advisory provided by the actual car product.\n\nHow do you explain a vulnerability in a short and concise manner without using any technical terms?\nA vulnerability is a weakness in a system that an attacker can use to gain unauthorized access or control. It's like a bad door in your house that an intruder can use to sneak in. In this case, the bad door is in a software system and an attacker can use it to make changes to the system that they shouldn't be able to. It's important to fix this vulnerability by updating the system or fixing the bad door, so the intruder can't use it anymore.\n\n",
"The vulnerability in the car product allows attackers to access and modify user settings. These settings could include personal information, preferences, or other sensitive data. An attacker could potentially gain unauthorized access to this information or manipulate the settings to gain control over the car's functionality.\n\nTo prevent unauthorized access and maintain the security of the car's system, it is recommended to upgrade to version five point two two six or later. This update will address the vulnerability and ensure that the system's security is maintained. Additionally, implementing proper input validation and sanitization measures can help prevent attackers from exploiting the vulnerability.\n\nIt's important to stay vigilant and check for updates to ensure the car's system is secure and protected from potential threats.",
"The vulnerability in the car product allows attackers to access and modify user settings, which could include personal information, preferences, or other sensitive data. An attacker could potentially gain unauthorized access to this information or manipulate the settings to gain control over the car's functionality.\n\nTo address this vulnerability, it is recommended to upgrade to version 5.2.26 or later. This update will address the vulnerability and ensure that the system's security is maintained. Additionally, implementing proper input validation and sanitization measures can help prevent attackers from exploiting the vulnerability.\n\nUsers should stay vigilant and check for updates to ensure the car's system is secure and protected from potential threats.",
"The vulnerability in the car product allows attackers to access and modify user settings, which could include personal information, preferences, or other sensitive data. An attacker could potentially gain unauthorized access to this information or manipulate the settings to gain control over the car's functionality.\n\nTo address this vulnerability, it is recommended to upgrade to version 5.2.26 or later. This update will address the vulnerability and ensure that the system's security is maintained. Additionally, implementing proper input validation and sanitization measures can help prevent attackers from exploiting the vulnerability.\n\nUsers should stay vigilant and check for updates to ensure the car's system is secure and protected from potential threats.",
"The vulnerability in the car product allows attackers to access and modify user settings, which could include personal information, preferences, or other sensitive data. An attacker could potentially gain unauthorized access to this information or manipulate the settings to gain control over the car's functionality.\n\nTo address this vulnerability, it is recommended to upgrade to version 5.2.26 or later. This update will address the vulnerability and ensure that the system's security is maintained. Implementing proper input validation and sanitization measures can help prevent attackers from exploiting the vulnerability.\n\nUsers should stay vigilant and check for updates to ensure the car's system is secure and protected from potential threats.\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt",
"ytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\nytt\n"
]
},
The code for all this will be at the bottom of the page, but as the loop generations iterate we can see a decay in what’s being expressed down to ytt\n repeated over and over again. Naturally I have no capacity to debug that so, lets just observe and move on. It’s worth noticing as well that the version five point two two six which should be 5.226 got interpreted as 5.2.26. That could cause a problem in reality.
The deepseek x llama collab gave output like
{
"model": "deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
"input_prompt": "The product named jrc which has a medium severity memory safety vulnerability in regular storage place in the versions since but not including one hundred and twenty-seven point five eight nine up to but not including one hundred and forty-eight",
"generations": [
"Okay, so I need to write a security advisory for this product called jrc. The vulnerability is a medium severity memory safety issue in the regular storage place, and it affects versions from before 127.589 up to, but not including, 148. Hmm, the user also mentioned to keep it short and to the point, so I should make sure it's concise.\n\nFirst, I should start with a clear heading. The example given uses \"Security Advisory: Medium Severity Memory Safety Vulnerability in jrc\" which seems appropriate. It's straightforward and indicates the severity right away.\n\nNext, the affected product is jrc, and the versions are a bit tricky. It's from before 127.589 up to but not including 148. I need to phrase that correctly. Maybe \"versions prior to 127.589 and up to, but not including, 148.\" That makes it clear which versions are impacted without including 127.589 and 148 themselves.\n\nThen, the issue is a memory safety vulnerability in the regular storage place. I should explain what that means in simple terms. Memory safety issues can allow attackers to manipulate memory locations that shouldn't be accessible, leading to potential attacks. So, I can mention that this could allow unauthorized memory access,",
"Alright, I need to craft a concise and clear security advisory for the jrc product based on the provided information. The vulnerability is a medium severity memory safety issue affecting versions before 127.589 up to, but not including, 148. \n\nFirst, the heading should be straightforward, indicating the severity. The example provided is good: \"Security Advisory: Medium Severity Memory Safety Vulnerability in jrc.\"\n\nNext, the affected versions need to be clearly stated. The user mentioned versions prior to 127.589 and up to but not including 148. I should phrase this to exclude the endpoints. So, \"versions prior to 127.589 and up to, but not including, 148.\" That way, it's clear that 127.589 and 148 are not affected.\n\nThe issue itself is a memory safety vulnerability in the regular storage place. I should explain the consequence briefly. Memory safety issues can lead to unauthorized memory access, which is a significant security risk. So, including that the vulnerability could allow unauthorized manipulation of memory regions that shouldn't be accessible is important.\n\nFinally, the advisory should mention that users are advised to update to a fixed version as soon as possible. This directs them to take action without going into too much technical detail.\n\nPutting it",
"Okay, so I'm trying to help someone craft a security advisory for their product. The user provided some initial content and then a refined version. They want me to focus on creating a concise and clear advisory, removing unnecessary information and ensuring accuracy.\n\nFirst, I need to understand the details of the vulnerability. It's a medium severity issue related to memory safety in the jrc product. The affected versions are prior to 127.589 up to, but not including, 148. So, versions 127.589 and 148 are not affected. The vulnerability is in the regular storage place, which could allow unauthorized access to memory regions that shouldn't be accessible.\n\nThe goal is to create an advisory that's clear and actionable. The user provided an example:\n\n\"Security Advisory: Medium Severity Memory Safety Vulnerability in jrc\n\nThis advisory addresses a medium severity memory safety vulnerability in the jrc product. The issue affects versions prior to 127.589 and up to, but not including, 148. A memory safety vulnerability refers to improper memory management that could potentially allow unauthorized manipulation of memory regions that should not be accessible. Users are advised to update to a fixed version of the product as soon as possible to resolve this issue.\"\n\nThey also gave a refined version which is",
"Okay, so I'm trying to help create a security advisory for a product called jrc. The vulnerability is a medium severity memory safety issue. The affected versions are prior to 127.589 up to but not including 148. The problem is in the regular storage place, which might let someone access memory regions they shouldn't.\n\nFirst, I need to make sure the advisory is clear and concise. The user provided an initial version and a refined one. I should focus on removing any unnecessary info and ensuring everything is accurate.\n\nThe refined advisory starts with the title, then a brief description, the affected versions, a brief explanation of the issue, and the recommended action. It's pretty straightforward, but maybe I can make it even more concise.\n\nI should check if the affected versions are correctly stated. Prior to 127.589 and up to, but not including, 148. So versions 127.589 and 148 are not affected. That’s clear.\n\nThe description mentions memory safety vulnerability and unauthorized access to memory regions. Maybe I can rephrase that for clarity without losing important info.\n\nThe advisory ends with updating to a fixed version as soon as possible. That's a good call to action.\n\nI think the refined version is solid, but perhaps I can make",
"Okay, I'm looking at the user's request to refine a security advisory for a product called jrc. The vulnerability is a medium severity memory safety issue affecting versions prior to 127.589 up to, but not including, 148. The problem is in the regular storage place, potentially allowing unauthorized memory access.\n\nFirst, I need to ensure the advisory is clear and concise. The initial version provided was a bit wordy, so the refined version is better. It starts with a clear title, then a brief description, affected versions, a concise explanation, and recommended actions.\n\nI notice that the user mentioned \"regular storage place,\" which might be a specific term. I should keep it as is since it's technical jargon that the audience would understand.\n\nThe affected versions are clearly stated as prior to 127.589 and up to, but not including, 148. That's accurate and easy to understand.\n\nThe description of the issue is brief but informative, linking the vulnerability to unauthorized access. The recommended action is straightforward—update to a fixed version as soon as possible.\n\nI think the refined version is effective. It's concise, covers all necessary points, and uses clear language. There's no unnecessary information, so it meets the user's requirements.\n</think>\n\n",
"**Security Advisory: Critical Memory Safety Vulnerability in jrc Product**\n\n**Summary:**\nA critical memory safety vulnerability has been identified in the jrc product, affecting versions prior to 127.589 up to, but not including, 148. This flaw may allow unauthorized access to memory locations, posing a significant risk to system security.\n\n**Explanation:**\nThe vulnerability resides in the \"regular storage place\" mechanism, potentially leading to memory corruption or unauthorized memory access. This issue could be exploited to compromise system integrity or data confidentiality.\n\n**Recommendation:**\nImmediate action is required. Update the jrc software to the latest stable version (post 148) to resolve the vulnerability and enhance security posture. Contact support for further assistance if needed.\n\n**Affected Versions:**\n- All versions prior to 127.589\n- Up to, but not including, 148\n\n**Mitigation:**\nUpgrade to a fixed version as soon as possible to protect your system from this critical flaw."
]
},
In observation I found deepseek x llama to be better at capturing the correct numbers and keeping them consistent over the lifetime of the iterations, but it loves to up the severity of any given vuln and the constant Okay, I'm.... really kills it from an automation point of view. Maybe that’s a feature in more “reasoning” models. Unclear.
The winner is probably the phi-4 model with this as a representative example
{
"model": "microsoft/phi-4",
"input_prompt": "The product named Smart Fridge 8000 which has a low severity memory safety vulnerability in regular storage place in the versions since but not including twenty-one point seven six six up to but not including twenty-three",
"generations": [
"### Security Advisory: Smart Fridge 8000 Memory Safety Vulnerability\n\n**Product:** Smart Fridge 8000 \n**Versions Affected:** 21.7.6 to < 23.0.0 \n**Severity:** Low \n**Issue:** Memory Safety Vulnerability in Regular Storage Module \n\n#### Summary:\nThe Smart Fridge 8000 models from version 21.7.6 up to but not including version 23.0.0 contain a low-severity memory safety vulnerability within the regular storage module. This issue could potentially allow an attacker to execute arbitrary code or cause a denial of service by exploiting improper handling of memory operations.\n\n#### Impact:\n- **Arbitrary Code Execution:** An attacker with access to the fridge's network interface might exploit this vulnerability to execute arbitrary code.\n- **Denial of Service:** Improper memory handling could lead to a denial of service, affecting the fridge's normal operations.\n\n#### Recommendations:\n1. **Upgrade to a Secure Version:** Users are advised to upgrade to version 23.0.0 or later, where this vulnerability has been addressed.\n2. **Apply Patches:** If immediate upgrade is not feasible, apply the latest security patches provided by the manufacturer.\n3. **Network Segmentation:** Ensure that the",
"### Security Advisory: Smart Fridge 8000 Memory Safety Vulnerability\n\n**Product:** Smart Fridge 8000 \n**Versions Affected:** 21.7.6 to < 23.0.0 \n**Severity:** Low \n**Issue:** Memory Safety Vulnerability in Regular Storage Module \n\n#### Summary:\nModels 21.7.6 to < 23.0.0 of the Smart Fridge 8000 have a low-severity memory safety vulnerability in the storage module, potentially allowing arbitrary code execution or denial of service through improper memory handling.\n\n#### Impact:\n- **Arbitrary Code Execution:** An attacker could execute arbitrary code via the fridge's network interface.\n- **Denial of Service:** The vulnerability could disrupt normal operations.\n\n#### Recommendations:\n1. **Upgrade:** Upgrade to version 23.0.0 or later to resolve the issue.\n2. **Apply Patches:** If upgrading is not possible, apply the latest security patches.\n3. **Network Segmentation:** Ensure the fridge is on a secure network segment to limit potential exposure.",
"### Security Advisory: Smart Fridge 8000 Memory Safety Vulnerability\n\n**Product:** Smart Fridge 8000 \n**Versions Affected:** 21.7.6 to < 23.0.0 \n**Severity:** Low \n**Issue:** Memory Safety Vulnerability in Storage Module \n\n#### Summary:\nModels 21.7.6 to < 23.0.0 of the Smart Fridge 8000 have a low-severity memory safety vulnerability that could allow arbitrary code execution or denial of service due to improper memory handling in the storage module.\n\n#### Impact:\n- **Arbitrary Code Execution:** Potential execution of arbitrary code via the network interface.\n- **Denial of Service:** Possible disruption of normal operations.\n\n#### Recommendations:\n1. **Upgrade:** Upgrade to version 23.0.0 or later.\n2. **Apply Patches:** If upgrading is not feasible, apply the latest security patches.\n3. **Network Segmentation:** Ensure the fridge is on a secure network segment to reduce exposure risk.",
"### Security Advisory: Smart Fridge 8000 Memory Safety Vulnerability\n\n**Product:** Smart Fridge 8000 \n**Versions Affected:** 21.7.6 to < 23.0.0 \n**Severity:** Low \n\n#### Issue:\nA memory safety vulnerability in the storage module could allow arbitrary code execution or denial of service.\n\n#### Recommendations:\n1. **Upgrade:** Update to version 23.0.0 or later.\n2. **Apply Patches:** If upgrading is not feasible, apply the latest security patches.\n3. **Network Segmentation:** Place the fridge on a secure network segment to minimize risk.",
"### Security Advisory: Smart Fridge 8000 Memory Safety Vulnerability\n\n**Product:** Smart Fridge 8000 \n**Versions Affected:** 21.7.6 to < 23.0.0 \n**Severity:** Low \n\n#### Issue:\nA memory safety vulnerability in the storage module could allow arbitrary code execution or denial of service.\n\n#### Recommendations:\n1. **Upgrade:** Update to version 23.0.0 or later.\n2. **Apply Patches:** If upgrading is not feasible, apply the latest security patches.\n3. **Network Segmentation:** Isolate the fridge on a secure network segment to minimize risk.",
"### Security Advisory: Smart Fridge 8000 Memory Safety Vulnerability\n\n**Product:** Smart Fridge 8000 \n**Versions Affected:** 21.7.6 to < 23.0.0 \n**Severity:** Low \n\n#### Issue:\nA memory safety vulnerability in the storage module could lead to arbitrary code execution or denial of service.\n\n#### Recommendations:\n1. **Upgrade:** Update to version 23.0.0 or later.\n2. **Apply Patches:** Apply the latest security patches if upgrading is not feasible.\n3. **Network Segmentation:** Isolate the fridge on a secure network segment."
]
},
Not perfect by any means, but directly usable and sane at a glance. It’s unclear what the \n1, \n2 and \n3 are about, but we’ve got a fairly consistent string of text almost immediately and I couldn’t find totally off the wall output like qwen would give.
In short though they all have issues and I wouldn’t directly put this output in front of anyone who cared about the product in question. I thought it might be interesting to look at something a little more objective and after a bit of looking I found an interesting python library called textstat. This library aims to measure the complexity of text to a reader and it does some with some industry standard measures. To be clear I do not understand these measures, but I thought it might be neat to try out. I went with Flesch–Kincaid readability measure since it was the first in the list of examples and had the “higher number better” property. Eg. A higher number is easier to read.
Each model had its own distribution of readability changes over iterations. One of the phi-4 runs looked like
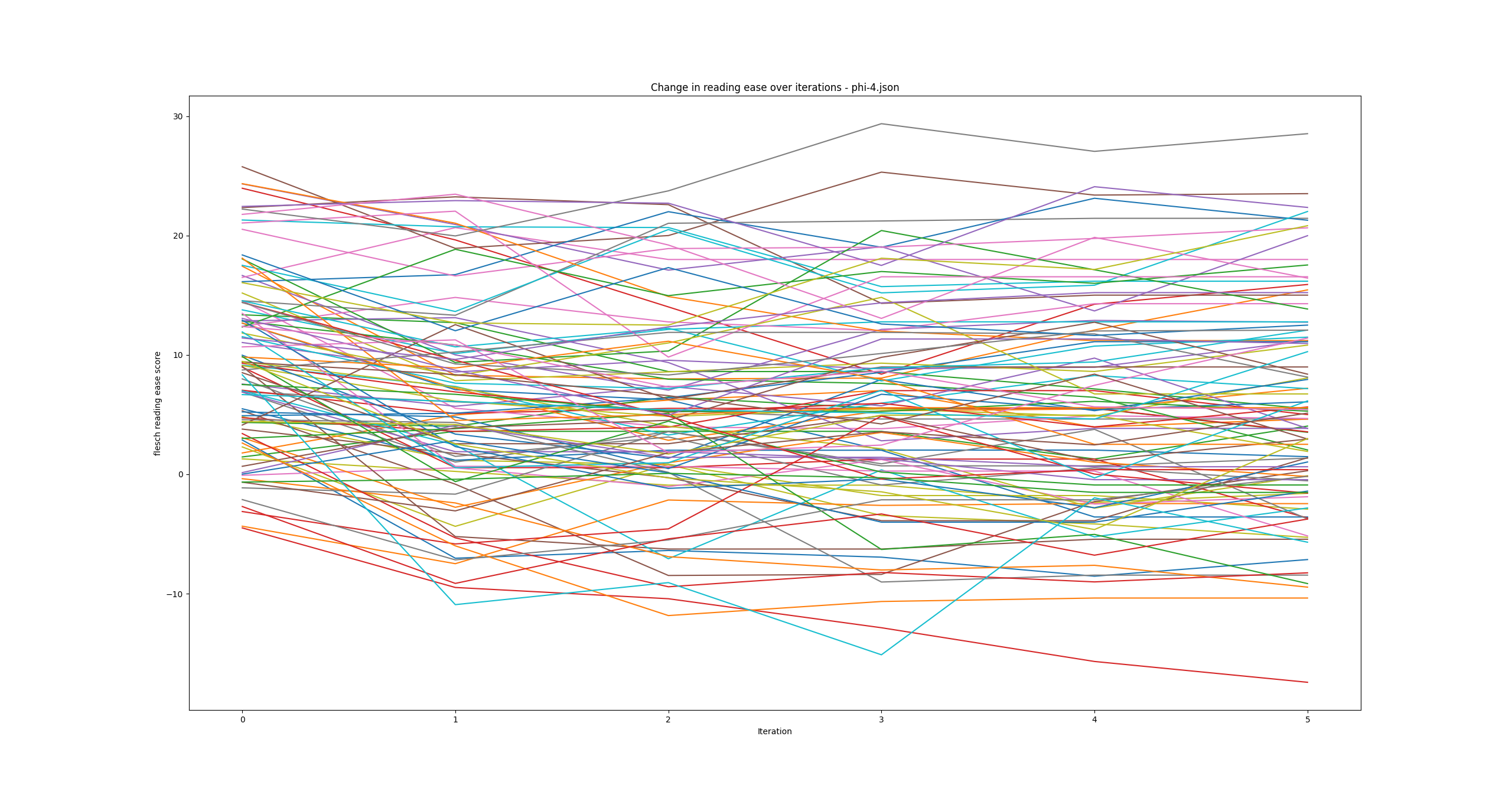
The top tick there is 30 and the bottom is -10. Negative scores are valid.
Each model had its own flavor of distribution and I’m not sure what questions to really ask of the data, so I won’t dwell on these. What I thought might be more interesting is comparing the models against each other.
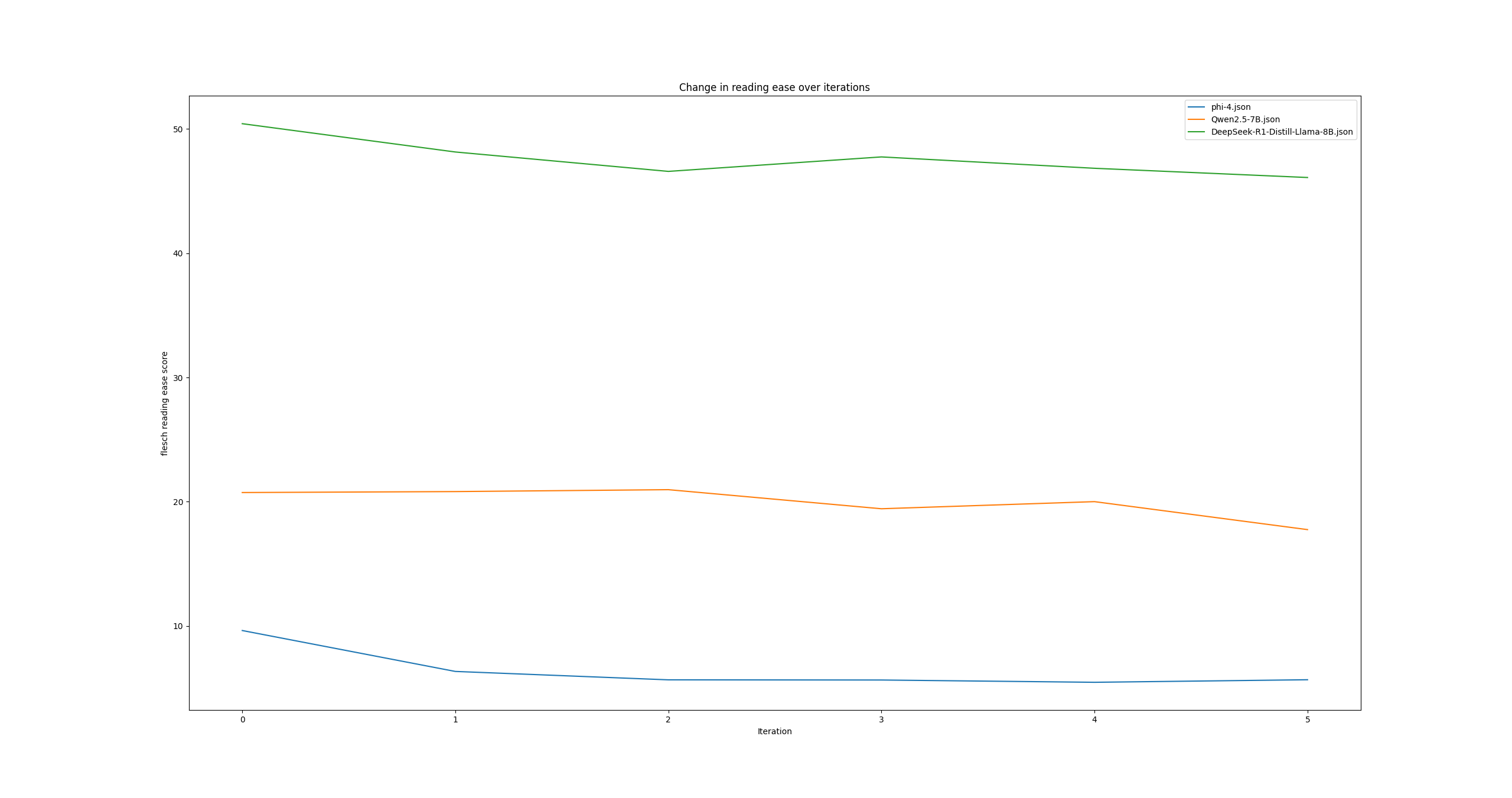
The top tick on this one is 50 and the bottom one is 10. Phi-4 is at the bottom in blue, Qwen in orange in the middle and Deepseek in green at the top with the easiest to read descriptions.
What seems to be common is that each model reduces the readability over iterations. Looking back at the phi-4 runs all plotted out on their own line I’m not sure I would have guessed that the readability scores will average lower, but it’s interesting to see. It’s also interesting that each model also has its own band of readability which does match my observation above. For context a score of 10 is deemed as a Professional reading level while 50 is deemed to be early college level. The observed differences are far less significant than the starting point for each model as well, though in the case of Phi-4 it’s possible the formatting is what’s driving the score down so much.
The conclusion?
Advisory publication is an act of creation. It is an art form. It is not a probabilistic generation question and so I do not see value in LLMs for advisory publication. Research tool? Maybe. Style guide checker? Sure, why not. Generator? Absolutely not.
thanks for reading
# pip install accelerate
from pathlib import Path
from pprint import pprint
from huggingface_hub import login
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import num2words
import random
import torch
import json
from dataclasses import dataclass, asdict
@dataclass
class PromptLineage:
model: str
input_prompt: str
generations: list[str]
def add_generation(self, new_text):
self.generations.append(new_text)
def get_most_recent_generation(self):
return self.generations[-1]
def random_versions():
upper = random.randrange(1, 256)
lower = round(random.uniform(0.1, upper), 3)
upper = num2words.num2words(upper)
lower = num2words.num2words(lower)
range_phrases = [
f"from {lower} up to but not including {upper}",
f"since but not including {lower} up to {upper}",
f"from {lower} up to {upper}",
f"since but not including {lower} up to but not including {upper}",
]
return random.choice(range_phrases)
def random_prompt():
product_names = [
"Yellow Vest Linux",
"Elaborate Text Storage Service",
"Datcord",
"jrc",
"Kazoo",
"Doors",
"An actual car",
"Smart Fridge 8000",
]
product_components = [
"user settings",
"regular storage place",
"secret storage place",
"transport",
]
severity = [
"low",
"medium",
"high",
"critical",
]
problems = [
"cross site scripting",
"memory safety",
"data exposure",
"logic injection",
"hard coded credentials",
]
prompt_string = (f"The product named {random.choice(product_names)}"
f" which has a {random.choice(severity)} severity {random.choice(problems)}"
f" vulnerability in {random.choice(product_components)}"
f" in the versions {random_versions()}"
)
return prompt_string
def improve_advisory(pipe, prompt):
messages = [
{"role": "system", "content": "You are an editor tasked with ensuring complete, concise and correct advisories are sent out for our users. Remove unnecessary content and refine the advisory provided. Only reply with the new advisory."},
{"role": "user", "content": prompt},
]
outputs = pipe(messages)
result = outputs[0]["generated_text"][-1]
return result["content"]
def generate_advisories(model, count):
pipeline = transformers.pipeline(task="text-generation", model=model, device_map="auto", dtype=torch.bfloat16)
prompt_evolutions = []
for i in range(0, count):
prompt = PromptLineage(
model,
random_prompt(),
[])
messages = [
{"role": "system", "content": "Write a security advisory for the product and problem provided. Keep it short and to the point"},
{"role": "user", "content": prompt.input_prompt},
]
outputs = pipeline(messages)
prompt.add_generation(outputs[0]["generated_text"][-1]["content"])
for i in range(0,5):
prompt.add_generation(improve_advisory(pipeline, prompt.get_most_recent_generation()))
prompt_evolutions.append(asdict(prompt))
return prompt_evolutions
## Uncomment the one you want to run
# model = "Qwen/Qwen2.5-7B"
# model = "microsoft/phi-4"
model = "deepseek-ai/DeepSeek-R1-Distill-Llama-8B"
with open('DeepSeek-R1-Distill-Llama-8B.json', 'w+') as f:
json.dump(generate_advisories(model, 100), f)